
Performance of ADPCM in Frame Erasures
Many present and proposed wireless communications systems employ the speech standards, Adaptive Differential Pulse Code (ADPCM), because it offers high quality, low delay, and low complexity. When transmission errors occur, the coded speech will have error propagations. And, transmission impairments may cause the loss of entire frames of coded speech, the performance of speech will decay rapidly. So, we will measure the performance of speech in frame erasures.
ADPCM :
ADPCM is a waveform speech coding. it is used to adaptive quantization and adaptive prediction.
In this final project, we report the performance of the ADPCM when frame erasures occur. And, we try to find better methods which can reconstruct speech during erasures to improve the quality of the corrupted speech.
Four Methods of Speech Reconstruction During Erasures :
a) Silence Substitution :
When a frame erasure is detected, all the bits in that frame are replaced by the lowest quantization level. A simple error detection scheme or a signal from the channel decoder indicating a frame error is sufficient to perform silence substitution.
b) Fixed Frame Repeat :
The input to the decoder is buffered and when a frame erasure is detected, samples delayed by 10 ms were introduced to the decoder input. If frame erasures are longer than 25 ms, the input is scaled down to the lowest quantization level.
c) State Reserving :
The state is saved when frame erasure is detected. The state in the end of frame erasures is replaced by reserving the state saved in the beginning of frame erasure.
d) Encoder and Decoder Reset simultaneously :
The encoder and decoder reset simultaneously at a constant interval. The quality of encoder and decoder reset simultaneously is poor than that of no reset during no frame erasure. But, in high Frame Error Rate (FER) the performance of encoder and decoder reset simultaneously is better than that of no reset.
Environment :
a) speech samples
- sampling rate : 8 kHz
- speech length : 6.97 sec
b) ADPCM
- linear
- quantization bits : 4 bits (data rate : 32 kbps)
c) frame length
- 20 ms
d) frame error rate (FER)
- 0.1、0.05、0.025、0.01
e) segment SNR (SSNR)
- segment length : 16 ms
Experiment results :
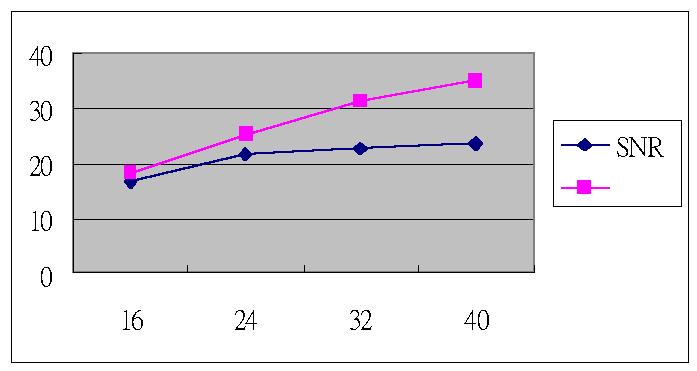
a) SNR & SSNR at different data rate
| Data Rate | 16 k | 24 k | 32 k | 40 k |
| SNR | 16.55715 | 21.63328 | 22.68998 | 23.68455 |
| SSNR | 18.44427 | 25.3381 | 31.42663 | 34.93507 |
b) Silence Substitution
c) Fixed Frame Repeat
d) State Reserving
e) Encoder and Decoder Reset Simultaneously
e) SSNR of Experiments
| FER | 0 | 0.01 | 0.025 | 0.05 | 0.1 |
| Silence Substitution | 31.32092 | 29.34896 | 25.77643 | 19.43691 | 11.23208 |
| Fixed Frame Repeat | 31.32092 | 29.38698 | 26.10405 | 20.15194 | 13.22028 |
| State Reserving | 31.32092 | 29.96891 | 27.2553 | 22.87107 | 15.63003 |
| Encoder & Decoder Reset simultaneously | 25.20946 | 24.80734 | 24.12372 | 22.92385 | 20.95093 |
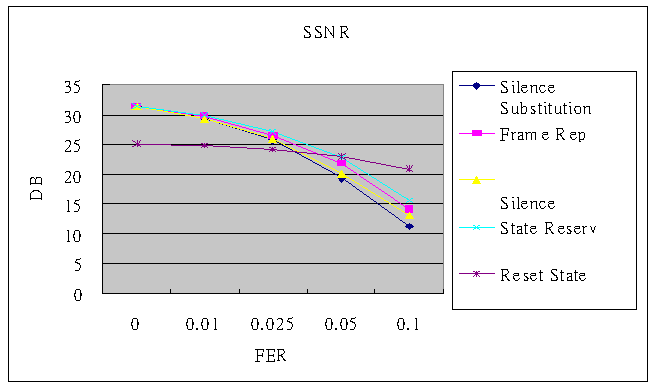
Silence substitution is the simplest method to reconstruct the corrupted speech. And, the performance of state reserving method is better than others. In high FER the performance of encoder & decoder reset simultaneously is better than others and avoid error propagation efficiently.