MPEG是動態視訊專家小組(Moving
Picture Experts Group)的簡稱,
1988年ISO/IEC(International Organization
for Standardization/
International Electrotechnical Commission)對動態視訊與語音壓縮標
準提出的壓縮準則,如今已廣泛地被使用在CD-ROM的視訊應用。然而當初
MPEG-1制定時,其解像度只有350*240*30,以此解像程度每當用於點腦
螢幕上播放時,由於電腦螢幕的要求過高,所以得出的效果都不堪為使用
者所滿意,故其並不適合做視訊傳播的應用,因此ISO/IEC在1990年又開始
制定MPEG-2的視訊壓縮標準,增加了視訊應用範圍的彈性,其中包含了支
援不同的影像的解析度、增強畫面比率化的計算、加強時間和空間的資料
壓縮性能,最大的改善在於提高數位率和使用調整位元率(VBR)
的技術,
主要的應用包含了數位電視視訊的傳播、高畫質數位電視(HDTV)、及數位
儲存媒體的應用,例如DVD(Digital Versatile
Disk)。而MPEG-2壓縮標
準最後於1995年完成。
然而視訊壓縮有很多不同的壓縮標準,適用於不同的應用範圍,MPEG
算是最普遍地被應用於數位視訊服務及廣泛地被工業界接受的一個視訊壓縮
標準,所以我們也就針對 MPEG-2 視訊壓縮標準做研究與討論。
![]()
5.1 MPEG-2壓縮格式基本架構
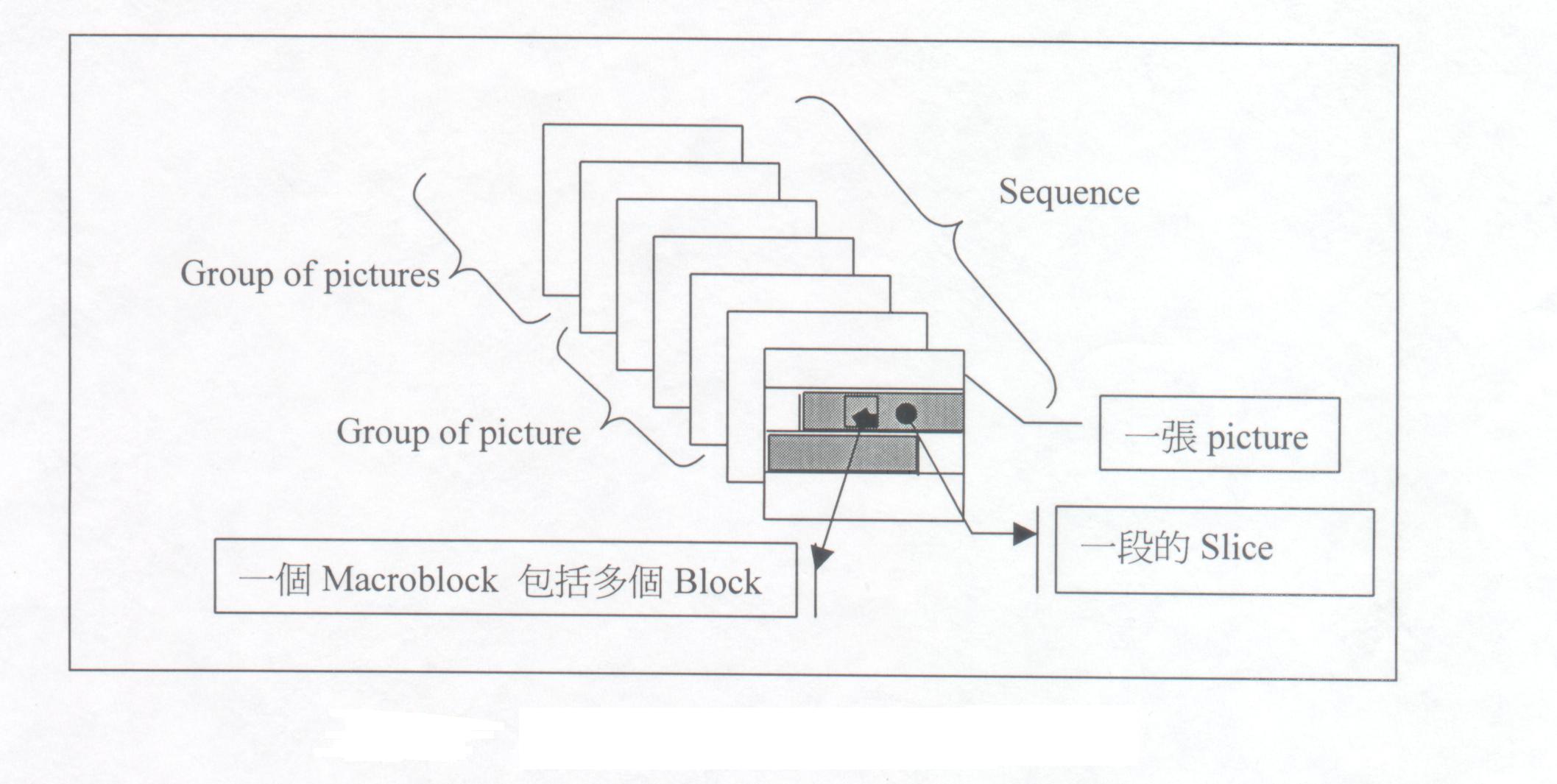
2. 影像群組(Group of pictures:GOP):
由一張 I 畫面及數張 P
及 B 畫面所組成,而 M 與 N 是用來描述一
GOP結構的參數,M 代表在一 GOP 裡的畫面總數目,N
代表兩個連續的 P
畫面的距離。然而一 GOP 也是視訊序列隨機存取的基本單位。
3. 影像(Picture):
由數個片段(Slice)所組成,為最主要的編碼單位,主要有三種影像
編碼的型態 I、P、B。
4. 片段(Slice):
由數個大區塊(Macroblock)所組成,主要將Picture作水平且固定單
位的切割,描述了在影像中的垂直位置,是訊號同步及錯誤控制的最小單位。
5. 大區塊(Macroblock):
由四個亮度信號(Luminance)區塊(Block)及數個色彩(Chrominance)
信號區塊所組成,例如:4:4:4、4:2:2、4:2:0。然而色彩信號區塊的數目是依
據影像數位化的取樣格式所決定。大區塊是移動估測及移動補償的基本單位,
描述了編碼型態、移動向量及在片段中距離第一個大區塊的相對位址。
6. 區塊(Block):
包含量化後的畫面資料,由8*8的像素所組成。
MPEG 定義了三種畫面壓縮模式I畫面、P畫面、B畫面:
(1) I 畫面(Intra-coded pictures):
僅使用本身的資料進行編碼經量化後再經
VLC ( Variable Length Coding)
編碼,沒有參考其他畫面的資料。所以在解碼時可以做為解碼的切入點,供隨
意擷取開始位置,不需參考其他畫面的資料,可以單獨進行解碼。I
畫面是一
視訊序列或一畫面群組的第一張,隨後在畫面群組裡的
P 畫面與 B 畫面都會
參考到它的資料,所以在網路傳輸時需要特別保護其畫面資料的遺失,以免造
成隨後畫面影像品質的損害。由於編碼獨立,不須參考其他畫面,享受消除時
間軸上多餘性之好處,因此壓縮率較差。
(2) P 畫面(Predictive coded pictures):
在解碼時,會使用到參考畫面(Reference
picture)的資料,這些參考畫
面為前面較早被播放的 I 畫面或 P 畫面,而參考的位置就是以移動估測所產
生的移動向量來表示,若找不到最適合的大區塊時,則使用Intra模式編碼。
P畫面是由數個Intra模式編碼與預測模式編碼的大區塊(Predictive
coded
macroblocks)所組成。由於參考前一I 畫面或
P 畫面且以動態補償方式預測
編碼,其編碼效率較高。
(3) B 畫面(Bidirectionally predicted pictures):
在解碼時,會使用到前面及後面兩個方向參考畫面的資料。如同
P 畫面一
樣,畫面資訊在參考畫面找不到相似的大區塊時,會使用
Intra模式編碼。參
考前後畫面做動態補償預測編碼,擁有最高的編碼效率,本身不再做為其他預
測編碼用。
而這三類的畫面在
Group of picture 中並沒有一定的安排次序。但是排
列方式會影響視訊壓縮效率與隨機處理的能力。
![]()
5.2 MPEG-2壓縮格式編碼和解碼原理
為了取得高壓縮比效果,
MPEG 採用了複合式多種壓縮技巧,首先是以區
塊為基礎的動態補償 (block-based motion compensation)
方法,利用前一畫
面至目前畫面內容之預測 (prediction) ,或是由前一畫面其下移畫面至目前
畫面內容之內插預測 (interpolation prediction),其預測的誤差值
(差異值)
,再利用 DCT 轉換除去空間上的相關性,並配合量化
(quantized) 程序略除
不重要的資訊,最後經由 VLC (variable length
coding) 方式編碼後與動態
向量複合產生視訊壓縮編碼。
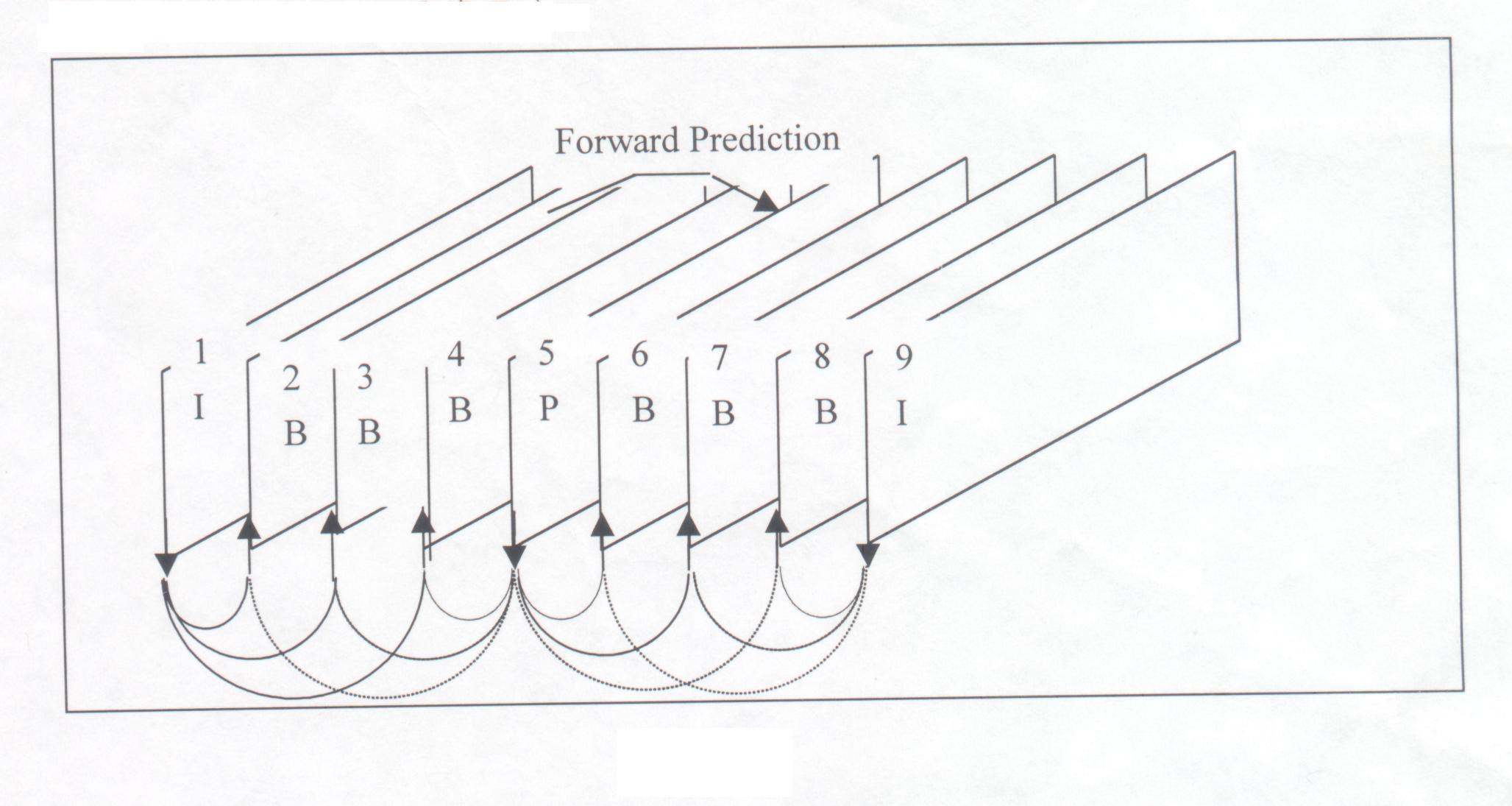
我們對於上述的 (block-based
motion compensation) 方法、預測
(predicition)方法以及使用內插預測( interpolation
prediction ) 的
方法舉一實例作說明。如上圖所示,我們列出一
Group of picture (包含
圖像I、圖像B及圖像P) :在這範例中,可以發現第一張圖像
I 為獨立編
碼,它與其它圖像沒有任何關連。第五張圖像
I 是參考第一張圖像 I,此
種編碼方式為順向預測。而第二張圖像 B 不僅參考了第一張圖像
I 還包
括了未來第五張圖像 P,此種作法稱為內插預測
(interpolation prediction)
的方法。 Group of picture 中其他部份可按不同圖形型態依此類推。透過
動態補償的方式,消除畫面間時間和空間的關聯性,僅用最小的資料量來記
錄彼此間的差異,也就是利用Motion Vector來記錄,如此可大大的增加壓縮
的效率。
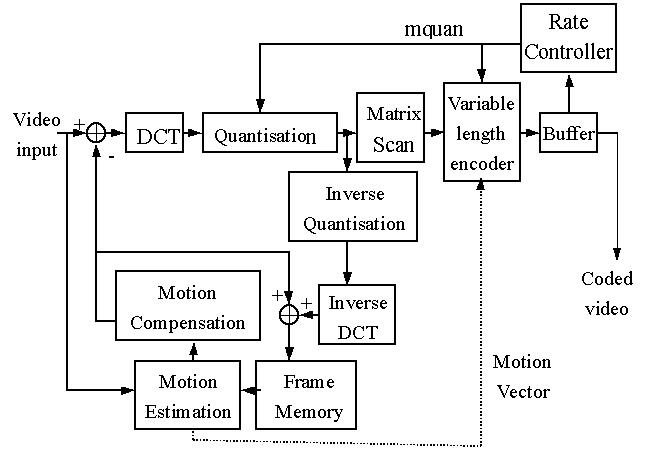
上圖為MPEG-2 單層視訊編碼器的流程圖。在編碼端,原始影像首先根
據畫面編碼的模式來進行相對的處理程序。若為
I 畫面,則信號直接經過離
散餘弦轉換程序,若為 P 畫面或 B 畫面,則信號經過移動預測
(Motion
Estimation) 來計算移動向量 (Motion Vector)
及隨後的移動補償(Motion
Compensation),然後原始影像與重建影像的差異值再經過離散餘弦轉換程序
將空間信號轉換成頻率信號。轉換後的頻率訊號根據畫面編碼模式相對應的
量化矩陣(Quantization matrix)進行量化程序,以減低數值的動態的區域
。因為量化後的矩陣是二維矩陣,所以隨後將量化後的二維資料掃描成一維資
料,最後再進行可變長度編碼(Variable length
coding)。編碼完後的資料
流如果沒有辦法得到token,也就是傳送許可,則先被存放在緩衝器
(buffer)
內,直到有token時才被傳送出。速率控制器
(Rate Controller) 是我們設計
來控制資料流輸出量的機制,如圖所示,他可以根據現在的網路使用狀況,回
饋(feedback) 到量化器以其位元長度編碼器來動態調整編碼的輸出量。例如網
路非常雍塞的情況下,速率控制器即回饋到量化器控制其量化基準減少,也就
是量化出的位元量較少,當然影像品質也就相對的降低,或者是控制位元長度
編碼器同樣使其編碼量減少來減低資料量以降低對網路的負荷。
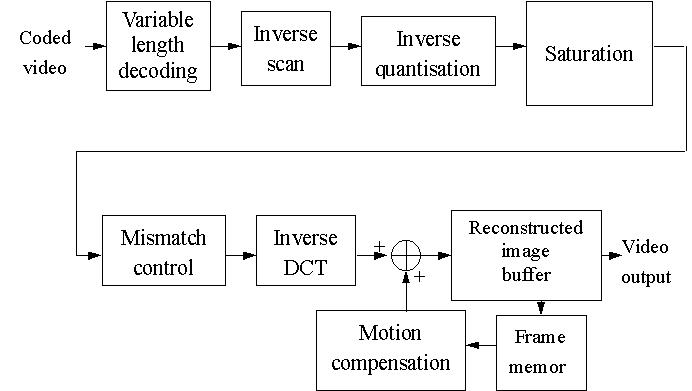
上圖為解碼端,則以反方向的程序進行解碼。接收到通道傳來的信號後直
接進行位元長度解碼,然後將一維化的資料轉換成二維的矩陣然後反量化,再
經過飽和 (Saturation) 以及不符合控制 (Mismatch
control),以上兩個動作
是預防在反量化的過程中矩陣有誤差以及錯誤,利用以上兩種動作將其更正回
來。然後經過反離散餘弦轉換將頻域的信號再轉換為空間的信號,如此以將信
號回復成壓縮前的資料流,再將這些資料流作整合,也就是在Reconstructed
image buffer中將接收到的資料再還原成原來的畫面,若為第一張
I 畫面則直
接進行還原的工作,隨後的畫面則透過 Frame
memory 將畫面存起來,再透過
動態補償的動作將隨後只記錄差異值的畫面還原成壓縮前的狀態。
![]()
5.3 可調性MPEG-2分層架構
MPEG-2視訊壓縮標準有一較重要的特徵就是視訊編碼的可調性(calability)
,它能將視訊編碼成兩層或多層的壓縮視訊,用不同位元符號的格式來表示各層
資料流的型態,亦即是在 Header 中加入表示各型態的符號,以符合各種視訊應
用的需求;而不用為了特定的應用,使用不同的視訊壓縮標準。但從編碼的角度
來看,可調性視訊編碼比傳統單層視訊編碼的複雜性高。然而因為可調性視訊能
提供較好的錯誤復原力(Error resilience),當視訊的資料流在網路上傳送時
,有時會因為網路壅塞或訊號干擾造成視訊資料的錯誤或遺失,在這種情況下,
我們如果能不增加頻寬的使用量,用分層的設計技術來讓較重要的資料有較高的
保證,也就是說若網路能支援兩種優先權的傳送方法,例如ATM網路支援高優先
權的細胞(Cell)傳送與低優先權的細胞的傳送。這邊介紹的可調性MPEG-2編碼
技術將視訊編碼成雙層的壓縮視訊,即基礎層(Base
layer video)和增強層
(Enhancement layer video),基礎層傳送於高優先權的通道而增強層傳送於
低優先權的通道,當接收端接收到兩層的資料時,基礎層的視訊能自己單獨地解
碼,提供基本的影像品質;而增強層視訊包含較少重要的資訊,若發生資料遺失
時,則對視訊品質影響不大。若兩層的視訊資料都能夠被正確的解出將擁有更佳
的影像品質。
利用可調性的特性,將使可調性MPEG-2編碼技術能提供較有彈性的視訊傳
輸方法,以解決網路異質性(Heterogeneity)的問題。因為在視訊傳播過程中,
各個子網路的狀況不見得相同,伺服器端到各個接收端的網路頻寬都不盡相同
,若將視訊編碼成雙層視訊,接收端能根據自己網路的頻寬,選擇性的接收部
分或全部的視訊層,而提供相對應的影像品質。
接下來介紹一種可調性MPEG-2壓縮機制的編碼和解碼技術,就是SNR可調
性MPEG-2視訊編碼器與解碼器。主要的運作方式是根據所給定的基礎層和增強
層位元產生比率 (本實驗中是給定1:1) 經過離散餘弦轉換後,將重要的DCT係
數(較低頻的係數) 、標頭(Header)、與移動向量的資料由高優先權的基礎層
來傳送以保證基本的影像品質,而離散餘弦轉換的誤差值以及一些較不重要的
DCT係數 (較高頻的係數) 則由剩餘的頻寬,也就是次優先權的增強層來傳送。
以下分別介紹SNR可調性壓縮技術的編碼器和解碼器。
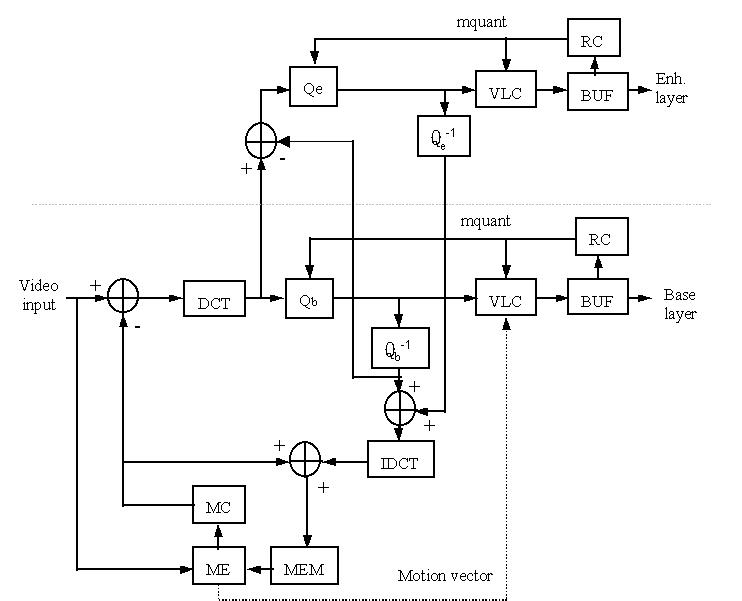
上圖為SNR可調性視訊編碼器的方塊圖,水平虛線下的區塊圖
— 也就是
基礎層 — 和原來的單層MPEG-2解碼流程是一樣的,主要是增加了水平虛線
上增強層編碼的部份。首先基礎層的編碼中,先進行離散餘弦轉換將空間轉
換成頻率,使較重要的大部分資料集中在低頻,對於影像品質較無影響的高
頻信號散步在高頻。再來經過量化器,使用自訂的量化位階大小,可以照自
己所要的影像品質自訂,當要求位階越大時,資料量越大,影像品質也就越
好,而此層量化器的主要目的是編出低位元率以及基本要求的影像品質。量
化後的資料流經過位元長度編碼,也就是將出現機率較高的信號用較少的位
元來轉換,較低的用較長的位元來表示,如此可以減少資料量在網路上的傳
送。而量化前頻域分佈的係數和反量化後係數的差異值,也就代表量化的誤
差,再經過增強層的量化器進行量化,產生增強層的資料來源,同樣經過位
元長度編碼減少資料量後傳出。將增強層反量化程序後的係數回饋到基礎層
反量化程序後的係數,主要目的是消除量化過程中的誤差以及將高頻的DCT
係數也包含進來,如此做是為了使往後要參考該畫面的動態估測和動態補償
在使用時能有較高的精確性。
位元率控制器 (Rate
control (RC) ) 的目的為調整量化位階大小以及
位元長度編碼器的運作,達到我們要求的輸出位元率。例如基礎層的位元率
控制器可以產生較大的量化位階,以獲得較高壓縮率及粗略影像品質的壓縮
視訊,而剩餘的影像資訊再以較小的量化位階進行增強層的量化程序。
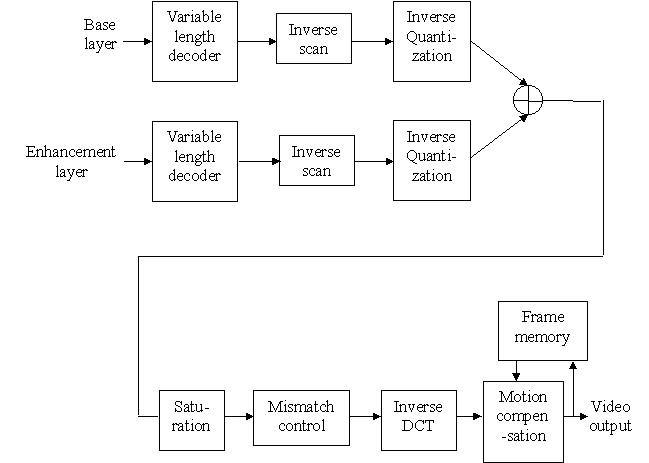
上圖為SNR可調性視訊解碼器的流程圖。基礎層和增強層的壓縮視訊分
別經過個別的可變長度解碼程序,將編碼端傳來的視訊解碼,接下來經過反
掃描程序,將一維的訊號重新還原為二維矩陣格式的訊號,矩陣再經過反量
化程序還原成原來在頻域的DCT係數,將基礎層和增強層的DCT係數矩陣相加
,其目的在修正DCT係數的數值,使其更精確地表示影像資料。在此之前,
兩層壓縮視訊的解碼程序都為各自獨立平行地進行。而飽和(Saturation)
控制程序,主要目的是更正DCT係數的遺失及錯誤,防止加總後的DCT係數
超過不合理的數值範圍,造成解碼時運算上的錯誤,所以將加總後的DCT係
數限定於之間,而超過的數值將以上限值所取代。不符合控制(Mismatch
control)程序的目的在防止較小非零的DCT係數輸入反離散餘弦轉換(IDCT)
後,產生零值的輸出。反離散餘弦轉換將影像的頻率訊號轉換成空間訊號,
轉換後的數值範圍將界於之間。移動補償程序則根據參考畫面的資訊、移動
向量與反離散餘弦後的係數相結合,產生最後的解碼輸出畫面。