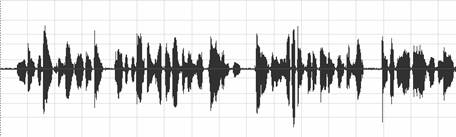
模擬迴聲測試:
實驗一開始,為了測試這個程式的消除效能,我們先測試在最理想情形下的結果,於是我們假設所謂的回聲和真實聲音的差別,僅在於能量的大小及時間的延遲,聲音變成回聲,在傳遞個過程中難免會有些能量損耗,又再把傳遞的時間考慮進去,因此我們決定了這個理想回聲的假設。
決定了這個假設之後,我們實際用麥克風與電腦錄音,經由麥克風輸入一組原始的音源訊號,再利用Adobe Audition軟體加入時間延遲,並將能量縮減,模擬出我們要的回聲。
考慮只有能量減低的情況:
我們先考慮只有能量減低,但無時間延遲的情況,當作是最理想的情形。將原始訊號能量下降3dB之後可以得出以下波形圖:
原始訊號波形:
經過回音消除後之波形圖:

由以上波形圖,我們可以發現在不考慮其他因素而僅有能量降低條件時,經過系統之後,可以得到近乎完美的回音消除效果。其ERLE值大約皆座落在50左右,顯示我們在最理想的情況下,ERLE值必須趨近於50。
考慮能量降低並有時間延遲之情況:
我們知道聲音的傳遞速度不可能無限快,在兩地之間的聲音傳播一定需要時間,也因此我們在前次實驗已降低3dB的聲音訊號的前面,利用Adobe Audition軟體加了一段靜音,做為時間的延遲。
加入0.08sec delay的原始訊號波形:
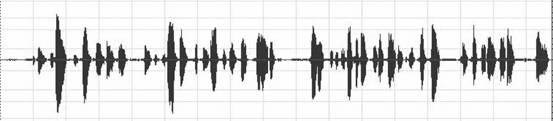
經過回音消除後之波形圖:

經過了回音消除之後我們發現,在某些地方消除的效果並不如我們所預期,得到的訊號能量依舊過大,導致回音依舊明顯,因此,我們又另外使用了一個NLP系統加以修正。
NLP系統的主要運作原理,是把所要處理的訊號能量降低。我們將此機制加在回音消除系統之後,使消除後的訊號能利用此系統將其能量降得更低,增進消除效能。
使用NLP降低訊號能量後的訊號波形:

經過一連串回音消除後,我們所製作的模擬回聲大約能使其 ERLE 值由原本的10左右變為座落於大約40左右,趨近於理想值的50,證明此方法有其可行性。
真實案例測試:
在做完模擬回聲的測試之後,我們開始嘗試想測試真實回聲。我們所使用的錄製真實回聲的方法,是在兩個不同的房間使用電腦連線,其中一端充當遠端,另一端則為近端輸入,藉由MSN的語音對話功能,我們在兩台不同的電腦使用麥克風對話,並用 Adobe Audition 軟體錄下對話內容。值得注意的是,由於我們需要的是由喇叭傳入麥克風,所造成的聲學回音,因此我們必須使聲音從喇叭輸出,而不能使用耳機。
Single Talk(With High Frequency):
我們先考慮在只有單端輸入(遠端)時候的情形。錄音的時候,在我們設定為遠端的一方對著麥克風說話,錄下自己的聲音,而在近端的一方則將喇叭打開,把由喇叭傳出的聲音(也就是我們要討論的聲學回音訊號),藉由麥克風錄進電腦中。
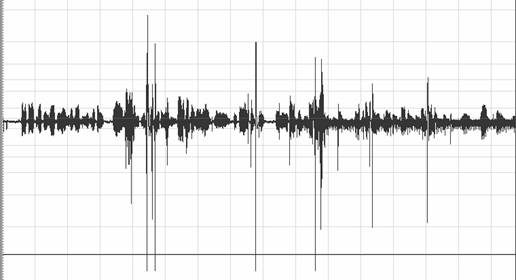 Origin Voice:
Origin Voice:

Echo Voice:
Final Voice:
由以上波形圖我們可以發現,由於我們所錄的回音訊號太大聲,能量太大了,因此在很多振幅較高的地方處理的不很完美,沒辦法得到我們預期的效果,這點稍後我們會另外討論,而在回聲訊號能量大小比較正常的地方,還是可以看到一些回音消除的效果。
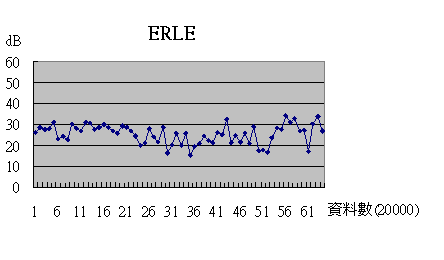
在此我們並使用Excel印出此次回音消除的ERLE值,其中的橫軸座標是每次處理的資料數,ERLE的處理方式是將訊號等分為好幾筆資料之後再做比較,因此此圖又可解釋為每筆資料處理前後的歧異度。
由這張圖我們可以看到,真實案例經由我們的回音消除系統處理之後,其ERLE值大約在20到30之間,很明顯的跟使用模擬回聲進行消除時的效果有很大的落差,因此我們判斷也許有其他我們尚不明瞭的回音產生的變因存在。
Single Talk(With High Frequency)With Delay:
由於我們所使用的麥克風設備不佳,收音效果不好,因此在錄音的時候我們將麥克風放在距離喇叭很近、幾乎接觸到喇叭的地方進行錄音,也因此正常回音應該有的時間延遲條件就被我們忽略了。為了改善此情形,我們又利用之前模擬回聲的方式再在訊號前面多加了一段靜音當作Time Delay,使其趨近真實情形。
在此我們又做了另一項假設,我們知道聲音的速度是V = 331 + 0.6t (t為攝氏溫度),我們假設一般車內免手持聽筒是至於儀表版上,與駕駛人的距離大約為0.5m左右,在一般情況下(1atm, 15oC)聲音傳播速度為340m/s,估計傳送距離0.5m大約需要費時1.5ms左右,因此我們在訊號前面多加了1.5ms的靜音空白,當作時間的延遲。
Final Voice With Delay:

Final Voice:



With Delay Without Delay
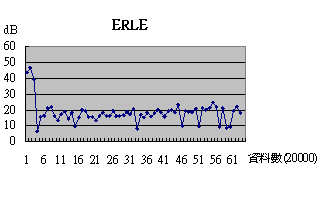
我們將有無時間延遲的兩種不同情形的ERLE圖放在一起比較,可以發現在With Delay情形的最一開始,ERLE值似乎略較Without Delay情形下稍高,我們猜測這是由於我們所模擬的time delay為一段不含任何訊號的靜音,因為不含訊號,因此消除的效果會很好(沒有訊號可以消)。
但是在一開始的靜音訊號期間過了以後,Without Delay情形下的ERLE值大約還是在30左右起伏,而With Delay情形下卻來來回回在20與30之間震盪,顯示其消除似乎不是很穩定,而且效果也比Without Delay情形還差,由於ERLE的工作原理是將原始訊號與消除後的訊號作比較,我們推測在多加了一段靜音訊號之後,在同一時間點上,加上時間延遲的訊號跟原始訊號歧異度將會比沒有時間延遲情形來的高,因此ERLE值在沒有時間延遲的情形下會比加入時間延遲情形較
Single Talk(With Low Frequency):
在測試完上一個ST之後,我們希望得知假設在不同情形狀態下的Single Talk對於此系統的回音處理效果是否會有影響,因此我們又用同樣的方法另外錄了一組低頻的訊號(男聲)來測試。
Origin Voice:
Echo Voice:


Final Voice:
由以上幾張波形圖中我們可以發現,在低頻情形下消除回聲的效果,似乎比在高頻的情形中要好。
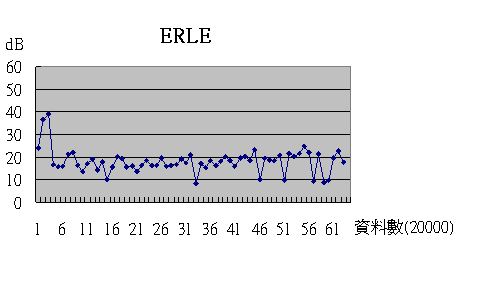
這是在ST訊號為低頻情形下的ERLE值分佈圖。數值相當平均,且大部分座落在20dB左右。
Single Talk(With Low Frequency)With Delay:
基於與高頻情形時同樣的理由,在低頻時後我們也以相同條件在資料前端多加一段1.5ms的靜音作為time delay。
 Final
Voice With Delay:
Final
Voice With Delay:

Final Voice:

 With
Delay Without Delay
With
Delay Without Delay
關於time delay的影響已在High Frequency中討論過,在此便不容贅述。
Compare Different Frequency:
在做完上述的實驗之後,我們將兩種不同情況拿來做比較。
High Frequency:

Low Frequency:

 High
High
High Frequency Low Frequency
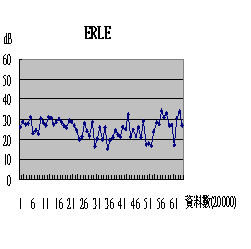
在上述的圖中我們可以發現,當在高頻的情況下,有許多地方消除的並不完美,剩餘的波形振幅還是很大;相較之下低頻輸入時,消除過後的波形就顯得較為平均。但我們又發現,雖然高頻時候在很多能量過高的訊號無法完美消除,但在許多消除成功的時間點所得到的結果卻又比低頻時候更加完美,這點可以由兩者的ERLE圖中查得。
但在做完此次實驗之後我們又發現了一個之前未考慮到的問題點:我們考慮了頻率這個變因,但是卻又忽略了其他種影響回音消除系統的可能,在輸入訊號時,我們利用了男生與女生先天聲音頻率的不同來作為實驗的控制變因,但是由於兩次錄音是由不同人所錄,也許在能量,也許在說話的緩急、甚至語氣間,皆不可能完全相同,也因此極有可能是這些外在的因素,促成此次實驗的結果。理想的情況下,我們應該用軟體將同一筆資料調頻,方能確保其餘變因維持不變,這是我們考慮為周詳之處。
Double Talk:
在實驗完ST情形之後,我們開始討論在DT情形下的回音消除情形。我們所使用錄製回音的方法是:在兩個不同的房間使用不同的電腦,利用MSN的語音對話功能通話,一開始由飾演遠端的一方先說,遠端對著麥克風將自己的聲音錄進去但不開喇叭,以免錄到不必要的回音與雜音;在遠端說話告一段落時,改由近端開始說話,而近端所使用的方法是利用麥克風將自己說話的聲音錄進去,並將喇叭連帶開啟,使遠端的音訊可以透過麥克風與近端語音訊號一同錄進去,用以實驗DT情形下的回音消除效果。
Far Voice:
Near Voice + Echo:

Final Voice:

在前幾張圖中,我們可以大略觀察出在DT情形下的回音消除狀況,但是在我們做出這個實驗之後,卻又意外的發現了之前忽略的問題點:我們會發現,依照理想結果,回音消除機制僅需要將遠端所產生的回音消除,但近端本身所輸入的聲音訊號必須要保留,但是我們做出的實驗結果竟然是把兩者皆一起消去了,這將會造成在遠端處幾乎無法收到任何聲音訊號,包括近端音訊與遠端回聲,是不好的結果。經過研究後我們發現,我們當初所使用來判斷是否有Double Talk的DTD裝置,其所使用的工作原理為比較兩個同時收到的訊號,回音會因為傳播過程與反射的關係造成能量流失,使其聲音聽起來較近端輸入的聲音訊號小聲,因此我們使用的DTD判斷原理為假設能量較小的訊號便是遠端的回聲,予以消除。
但是之前我們有提到,我們原先所使用的麥克風裝置設備不理想,必須在很近的距離才有辦法收音(所以才會有假設的time delay實驗),也因此造成了我們所錄到的回音,事實上的能量與近端輸入的聲音訊號能量相等,甚至超過,以至於再消除的過程中近端輸入訊號連帶的一起被消除了。
重新錄製並再次實驗:
由於發現了上述回音過大的問題,我們改善了原先錄音用的麥克風設備,得到比先前更理想的回音,並重新開始實驗。
Single Talk:
Origin Voice:

Echo Voice:

Final Voice:

Double Talk:
Far Voice:
Near Voice + Echo:
Final Voice:

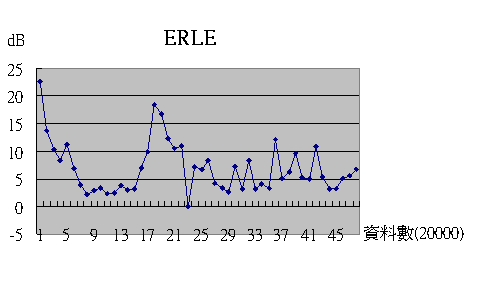
由以上的實驗波形中,我們可以看到第二度錄音實驗中,我們所使用的Echo Voice,能量遠小於Origin Voice,也就是在正常距離錄到的正常回音,也因此在第二度錄音後的實驗過程中,我們已經不需將原先假設的time delay考慮進去。
而我們更可以明顯的發現,在Double Talk情形之下,我們消除回音的過程中,並不會將訊號能量較大的近端語音訊號一起消除,而是保留下來,這也是我們所需要的較理想效果。
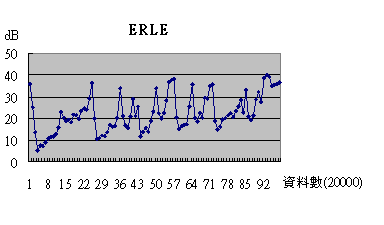
觀察Double Talk最後的ERLE圖示可以發現,在只有遠端語音訊號發生時,ERLE值大約座落在20dB左右,但是一旦近端訊號輸入時,ERLE值會瞬間下降,降到大約10dB,甚至更低,可惜我們仍不清楚造成此一結果的詳細原因。
注意事項與改善空間:
在做了這麼多組的實驗之後,我們發現了許多未考慮周詳的注意事項:
1. 在錄製聲音時,錄音設備裝置務必要求完備精良,因為較差的錄音器材,很有可能會因為其收音效果不佳,造成雜音過多,或是我們所遇到的錄不到回音之問題。
2. 錄製聲音時,務必要求錄音環境一致,盡量避免不必要的外在雜音產生,以求實驗變因相同,並減少不必要的雜音干擾。
3. 在假設影響回音消除的變因之後,實驗過程應要求僅控制變因改變,其餘變因必須相同。例如在考慮頻率是否對回音消除造成影響的實驗中,最好是可以使用同一組聲音訊號,利用特殊軟體加以改變頻率,力求其餘變因相同。
而我們在做了這次的專題之後,發現我們所使用的程式仍然有許多不足的地方,在此提出討論:
1. DTD判斷語音效能不佳。由於我們僅以能量的大小判斷是否為回音訊號,卻未考慮到萬一回音能量過高時將引起的消除效果不佳之情形,也因此更理想的判斷方式應該改為將近端麥克風所收到的兩筆資料分別與原始訊號做比較,近似度較高的判斷為原始訊號的回音,此種方法應較為準確。
2. 由ERLE圖中,我們可以發現到此機制中回音的消除效果似乎起起伏伏,有一定的週期性,但我們目前仍然不明其原因,上無法提出有效的改善方法。
![]()