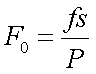![]()
|
|
|
|
知識庫
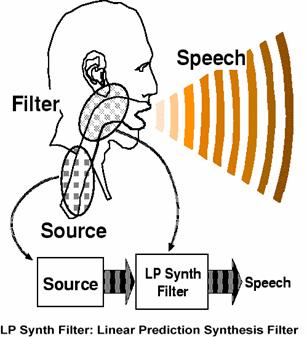
語音的產生過程是空氣從肺部發出,經由氣管通過聲帶及音喉,最後經口腔、胸腔、鼻腔的共振而發出。依聲帶的振動與否,在語音處理上,我們可以分為有聲與無聲兩種。為了方便分析, 我們根據發聲的方式,可以建立一個相對應的語音分析及合成的模型。我們稱之為Source-Filter Model。
- Source方塊為模擬聲帶因肺部內的空氣流振動而產生的聲波激勵源模型。 - Filter方塊為模擬從氣管到聲帶到口腔、 胸腔 、鼻腔的聲道模型。
語音訊號原本是一種時變、非穩態的訊號,但由於語音的變化緩慢。當在適當週期時我們可以視為非時變、穩態的訊號特性。因此在處理語音上我們常會把一連續語音長度分割成數個短時間的主音框來進行分析與處理。 有了以上的假設條件後,當取樣頻率為8KHz,其取樣週期約為90點下,語音訊號將近似穩態且具有週期性。此週期一般稱為基頻週期。以數學表示方式為
通常

|
|
|