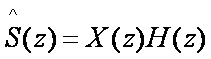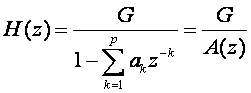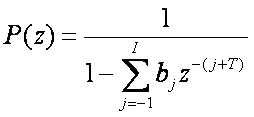![]()
|
|
|
|
知識庫
我們已經建立起語音合成的模型,為了處理分析語音,進而達到語音壓縮的目的,我們必須對激勵源訊號與聲道濾波器有精確的描述,才使得解碼端根據編碼端所給與的資料線索如LPC 係數或增益值,能得以重建原始的語音。我們使用的方法為線性預測(Linear Prediction)。其線性預測的概念是,在適當分割音框下,語音訊號具有變化緩慢的特性(即穩態),取樣點間的相關性非常地高且具有週期性;因此,目前的取樣點可由之前幾個取樣點的線性組合來加以預測而得。
數學表示方式為
其中 其階數越大的LPC模型越能準確反應原始語音的頻譜。因此大多數的語音編碼使用了10~16階的LPC模型。但實際上LPC的階數有限,在實施情況下只能濾除出短暫短時距的相關性。也就是其殘餘訊號無法接近真正激勵源,仍會存在長時距的語音相關性,為了能更近似噪音雜訊般的激勵源。仍需由基頻濾波器(Pitch Filter)來濾除此特性。
基頻預測也可以稱為長程預測(Long Term Prediction),簡稱為LTP。
其 經由LTP可以濾除經過LTP的殘餘訊號之長時距的相關性,因此使得近似雜訊的激勵源訊號得以還原。 |
|
|