![]()
|
|
|
|
知識庫
1 分析問題的方法
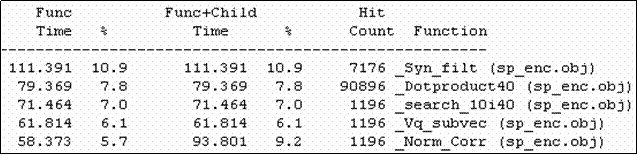
在分析中,我們需要知道的,首先是在AMR編解碼架構中,各個子模組耗費系統資源的比較。透過工具的使用我們可以得到如圖5-1所示的表。 (圖5-1 A Profile of AMR Analysis) 此表中,我們可見得最耗資源的前五名,都屬於編碼模組。而最甚者,是分析filter的函式。故我們最需要在此函式做加速的動作。
2 加速的方法 在加速過程中,我們需要施行三個步驟: - 找出數值的範圍。 - 浮點數直接縮減。 - 浮點轉定點。 其實浮點本身的表示並沒有什麼問題,只要有浮點運算器,使用浮點數並不會影響我們的運算時間。只是在沒有浮點運算器的情況下,我們所自稱的浮點數,都會被CCS的編繹過程,轉為相當冗長的指令集。所以要使執行的指令縮減,最好的方式,便是透過我們的分析,直接去定義數值。
2.1 找出數值的範圍 控制數值的第一步,便需要了解它的範圍在哪裡。知道範圍在哪裡,我們便可以確切地把握每一個bit都有其用處。剩下多餘的bit,便移到小數處作為精確度的加強。
2.2 浮點數直接縮減 所謂浮點數直接縮減,是在找出數值範圍後,縮減高位元處的冗位元,轉化為小數的部分。再以耳朵為準,去試出到底這個部分我們需要多少的小數位才夠使用?一但最高位元數與小數的位元我們都能夠掌握,我們便不再需要浮點的運算了。
經過前面的兩個步驟,我們直接把浮點數改成定點數,如此即大量地簡化了指令的運用。
3 分析加速結果 透過我們前面所介紹的加速法,我們將加速施加於syn_filt的函式上,並以圖表表示其結果比較:
(圖5-2-1 A Table before Acceleration )
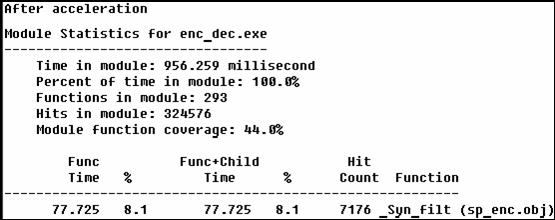
(圖5-2-2 A Table after Acceleration)
(圖5-2-3 A Table before Acceleration)
(圖5-2-4 A Table after Acceleration)
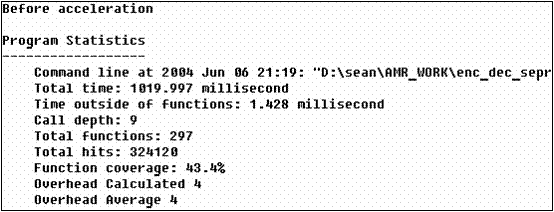
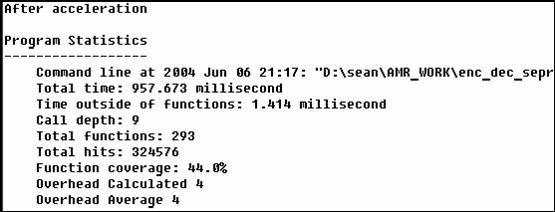
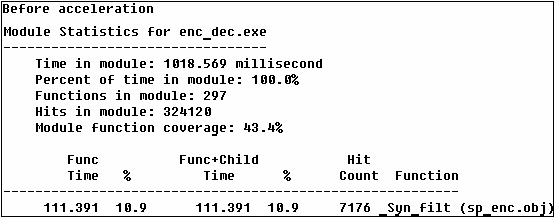
此處我們可以發現整個程式的執行速度由原本的1019.997ms變為957.673ms。而syn_filt函式在整個程式的負荷上,由原本的10.9%變為8.1%。可見得我們的加速是有效的。
|
|
|