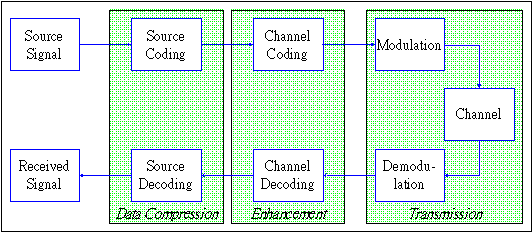
![]()
|
|
|
|
知識庫
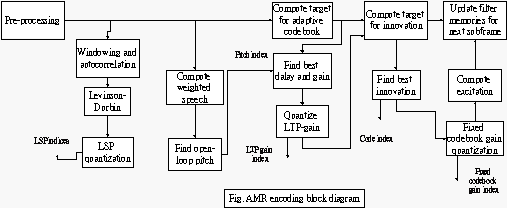
AMR 具有八種不同的編碼率
12.2、10.2、7.4、6.7、5.9、5.1、5 和4.75 k bit/s。此種編碼器使用了A-CLEP
(algebraic
code-excited linear predictive) 編碼架構如下圖所示。LPC合成器由兩個不同的激勵源向量所重建而得.分別是adaptive
codebook 與fixed codebook
重建出之語音訊號也是根據此兩種元素選擇出最佳的激勵源向量經過合成濾波器所得。此種選擇的目的是在兩個編碼簿中找出最佳化的激勵向量與增益使得預測的誤差為最小。
此種編碼器每個碼框長度大小為20ms,也就是在取樣頻率8kHz下,取樣點為160點,語音訊號將被分析成CELP的模型參數,這些參數包括adaptive codebook 與fixed codebook 兩本編碼簿的線性預估濾波係數值、索引值,與增益值…等等。其編碼流程主要分成以下兩大部份: 1.主碼框: 線性預估編碼係數轉換成LSP及量化適當分割四個子碼框為每個為5ms,以降低子碼框間的相關性。 2.子碼框: 輸入的語音訊號經由LPC濾波器分析而得到殘餘訊號(residual signal)以及增益值。這些參數值的狀態是時變性的會根據每一個子碼框的LPC殘餘訊號和激勵源訊號間的誤差來持續更新。其編碼步驟歸納如下: - 線性預測。 n 當知道語音訊號特性後,適當分割成四個子碼框下的自我相關性非常高(LPC基本概念)。因此參考過去兩個子碼框利用LTP濾波器來得到後兩個子碼框的短時距語音基頻資料,此時就可以完整預測得到四個子碼框的基頻資料,此階段除了要得到基頻訊號還加入了利用 Levinson-Durbin 演算法將之轉換到LSP(line spectral pair) Domain,以方便之後的量化壓縮。 - 開迴路基頻分析。 n 為了減少搜尋最佳適應性編碼簿的延遲,因此採用二階段作基頻搜尋。第一為開迴路搜尋在大範圍中取樣中求出第一階段的基頻延遲量估計值,而閉迴路搜尋中為在小範圍取樣點中,以第一階段的估計值當參考,再求出基頻延遲量與增益係數值,並將之量化編碼。 - Adaptive Codebook搜尋及增益值控制。 n 適應性編碼簿主要有目的為是找到最佳的預測基頻,並從編碼簿中計算得到編碼向量。此階段會得到的參數有基頻濾波器的最佳化的編碼向量及其增益值。 - Algebraic Codebook搜尋及增益值控制。 n 理論上經由上述的濾波器過濾後,剩下的已經非常近似殘餘訊號了。此階段目的為把經由LPC後剩餘的長時距訊號作編碼。其編碼方式是由一組包含10個非零脈衝,其中每個脈衝皆帶有正負號(+1 or -1),根據輸入的近似激勵源訊號,找出最接近的的一組脈衝組合,然後再將最佳脈衝組合的位置與振幅進行量化編碼。此編碼簿亦可稱為固定性編碼簿(Fixed codebook)取其字面意義也就是以最佳的已固定之脈波組合來代表原本訊號。每個子碼框分佈如下表所示
(表2-1 Potential positions of pulses in the algebraic codebook) - 對CodeBooks參數的量化。 n 適應性編碼簿和固定性碼簿的增益是使用7位元的向量量化,增益碼簿的搜尋是最小化原始語音最小化和語音訊號之間的平均平方權重誤差。 子碼框資料狀態更新
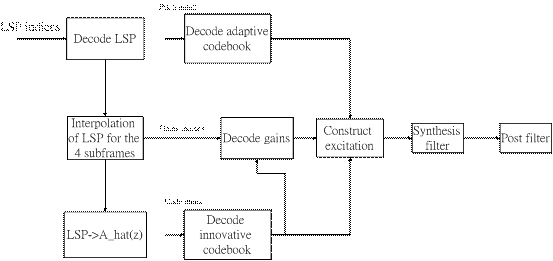
AMR解碼方塊較無編碼方塊複雜,其解碼功能區塊如下圖所示接收的資料封包內容,包括了 LSP向量索引參數、少數pitch lags、編碼向量係數值、以及pitch係數值、增益係數值…等等 其中LSP向量會轉換成為LP 濾波器的係數,插值入每一個子碼框架之後,合成器之激勵源就會被重建回來。再經過合成濾波器還原為語音訊號 這時只要再經過”Post濾波器”處理就會成為真正的語音訊號而輸出。
1.LP濾波器的係數合成 所接收的量化過LSP索引係數,將用來重建量化過LSP 向量激勵源,對每一個子碼框架而言,插值過後的LSP向量會轉換成LP濾波器的係數,而這也是用來合成重建出語音所需之參數之一。 2. 子碼框架中的解碼步驟 - Adaptive codebook 的解碼。 - Innovative codebook的解碼。 - Adaptive & Fixed codebook 增益值的解碼。 - 平滑化Fixed codebook的增益值。 - 除去Sparseness 處理。 - 計算出重建的語音訊號。
|
|
|